
多模态数据分析
多模态知识服务平台架构图如下所示:
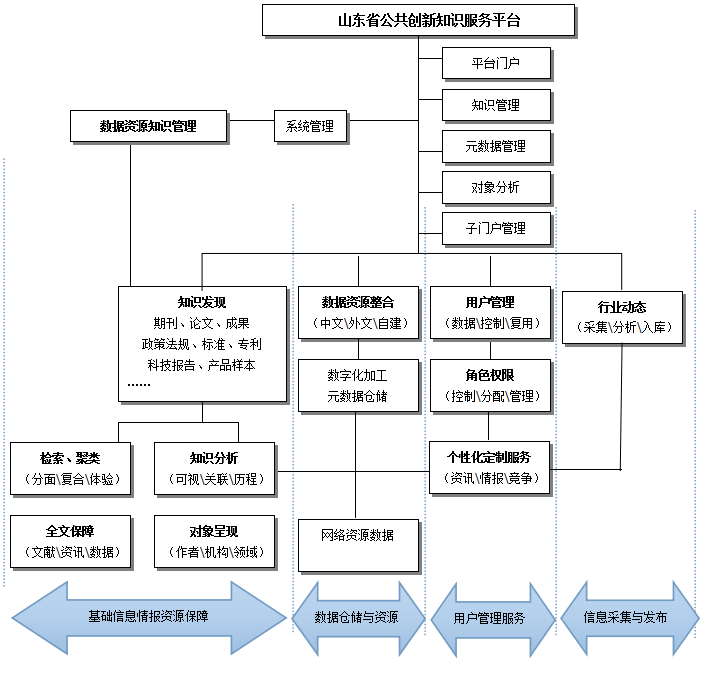
图1服务平台架构树状图
由上图可知,具体实现步骤可分为三步,首先是数据准备,其次是数据挖掘,最后是结果展示。
(1)数据准备
首先对领域内的相关数据进行批量采集,将不同来源的数据资源进行收集、清洗、标准化等处理,完成对数据的噪声去除、重复过滤、类型转换形成结构统一的基础元数据库。
数据准备阶段主要对知识发现的对象进行ID标识整理、粒度分析、关联呈现,如:
主题词词典——利用卡方检验、词频筛选方法,在符合主题词增词原则(文献增量与主题词增量比)的基础上构建主题词表,综合利用马尔科夫模型、信息熵、互信息、潜在语义分析、模式识别、复述等方法完成错词通用词识别与词间关系的计算(共现相关、同义、上下位、相似等)。
人物词典——从文献中提取作者,并构建作者特征(机构、主题、合作者、传媒、基金等),利用机器学习算法(朴素贝叶斯、近邻传播等)完成作者合并,实现重名消歧。
机构词典——利用模式匹配、机构实体识别等方法结合数据编辑人工处理,完成机构标准名称规范、层级关系构建、机构变更关联等。
(2)数据挖掘
以领域为核心对元数据库中的数据进行整合,形成专题数据库。同时构建一个知识发现系统,基于海量元数据资源,通过对数百亿数据关系的挖掘,本项目解析多个维度的文献资源知识对象,包括领域、主题、学者、机构、传媒、资助等,再通过聚类、数据挖掘、数据分析等技术完成数据到知识的转化,形成知识图谱、分析报告、趋势分析等多种新信息资源。
(3)结果展示
将专题数据库中的文献资源和通过知识发现系统获得新信息资源一起展示在信息服务平台上,通过对知识对象做唯一标识、深入挖掘、粒度分析,从而建立起蕴藏于各类文献之间,不同知识对象的直接关联,帮助用户快速形成对所需信息的结构性认识。同时,采用可视化的呈现方式,对学科领域的知识模型和知识对象的相互关联进行了宏观和微观的不同描述,方便用户直观认识学科发展方向、人物研究重点、机构的热门研究方向、研究主题的相互关联等内容,并能通过检索查询、关联点击、文献下载等功能让用户获取所需的信息资源。
(4)元数据采集和加工
本项目的数据主要有四大来源,按数据结构类型分为同构元数据和异构元数据,其中同构元数据主要是指来源于主流商业数据库的各类文献信息数据,异构元数据主要是来源于本单位的自有数据、与本单位达成战略合作的政府部门的官方数据、本单位在资源建设过程中利用爬虫在网络上采集的数据。这些元数据通过采集与加工放于元数据统一仓储云中。
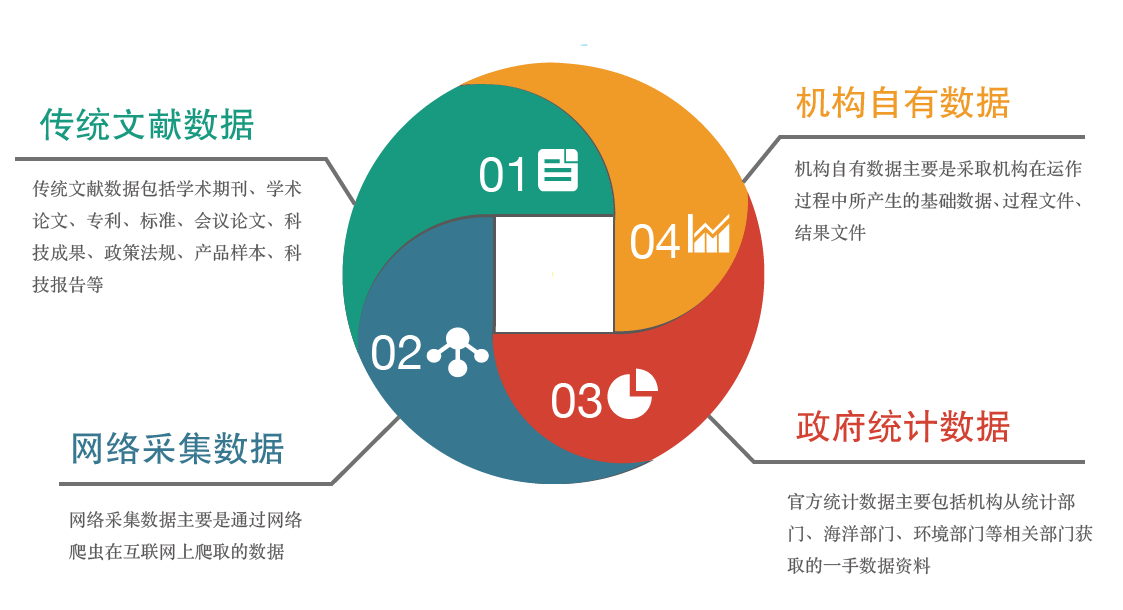
图2元数据来源构成示意图
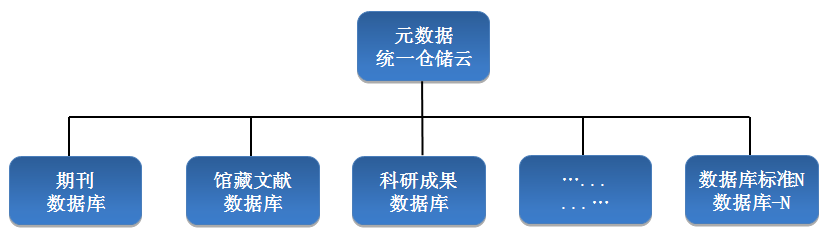
图3元数据统一仓储云构成示意图
